2024羊城杯hardsandbox
前言
这次羊城杯我和火箭发挥的异常的好,pwn5题出了4题,很可惜hardsandbox这题没出。主要是没见过RET_TRACE的沙箱,没有积累过此类板子。
题目
题目附件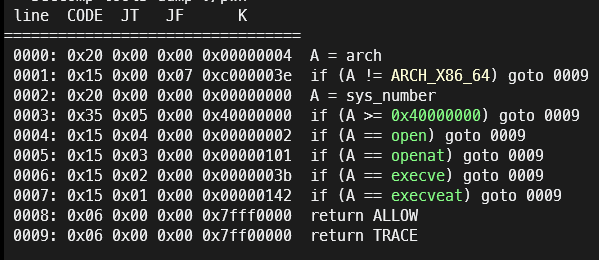
沙箱如上图所示,不仅仅限制了execve,连常规的orw也被限制了open和openat。
过这次的沙箱全部都是返回TRACE,要是比赛时机灵点可以在man上查找
man-seccomp
SECCOMP_RET_KILL_PROCESS (since Linux 4.14) This value results in immediate termination of the process, with a core dump. The system call is not executed. By contrast with SECCOMP_RET_KILL_THREAD below, all threads in the thread group are terminated. (For a discussion of thread groups, see the description of the CLONE_THREAD flag in clone(2).)
The process terminates as though killed by a SIGSYS
signal. Even if a signal handler has been registered for
SIGSYS, the handler will be ignored in this case and the
process always terminates. To a parent process that is
waiting on this process (using waitpid(2) or similar), the
returned wstatus will indicate that its child was
terminated as though by a SIGSYS signal.
SECCOMP_RET_KILL_THREAD (or SECCOMP_RET_KILL)
This value results in immediate termination of the thread
that made the system call. The system call is not
executed. Other threads in the same thread group will
continue to execute.
The thread terminates as though killed by a SIGSYS signal.
See SECCOMP_RET_KILL_PROCESS above.
Before Linux 4.11, any process terminated in this way
would not trigger a coredump (even though SIGSYS is
documented in signal(7) as having a default action of
termination with a core dump). Since Linux 4.11, a
single-threaded process will dump core if terminated in
this way.
With the addition of SECCOMP_RET_KILL_PROCESS in Linux
4.14, SECCOMP_RET_KILL_THREAD was added as a synonym for
SECCOMP_RET_KILL, in order to more clearly distinguish the
two actions.
Note: the use of SECCOMP_RET_KILL_THREAD to kill a single
thread in a multithreaded process is likely to leave the
process in a permanently inconsistent and possibly corrupt
state.
SECCOMP_RET_TRAP
This value results in the kernel sending a thread-directed
SIGSYS signal to the triggering thread. (The system call
is not executed.) Various fields will be set in the
siginfo_t structure (see sigaction(2)) associated with
signal:
• si_signo will contain SIGSYS.
• si_call_addr will show the address of the system call
instruction.
• si_syscall and si_arch will indicate which system call
was attempted.
• si_code will contain SYS_SECCOMP.
• si_errno will contain the SECCOMP_RET_DATA portion of
the filter return value.
The program counter will be as though the system call
happened (i.e., the program counter will not point to the
system call instruction). The return value register will
contain an architecture-dependent value; if resuming
execution, set it to something appropriate for the system
call. (The architecture dependency is because replacing
it with ENOSYS could overwrite some useful information.)
SECCOMP_RET_ERRNO
This value results in the SECCOMP_RET_DATA portion of the
filter's return value being passed to user space as the
errno value without executing the system call.
SECCOMP_RET_USER_NOTIF (since Linux 5.0)
Forward the system call to an attached user-space
supervisor process to allow that process to decide what to
do with the system call. If there is no attached
supervisor (either because the filter was not installed
with the SECCOMP_FILTER_FLAG_NEW_LISTENER flag or because
the file descriptor was closed), the filter returns ENOSYS
(similar to what happens when a filter returns
SECCOMP_RET_TRACE and there is no tracer). See
seccomp_unotify(2) for further details.
Note that the supervisor process will not be notified if
another filter returns an action value with a precedence
greater than SECCOMP_RET_USER_NOTIF.
SECCOMP_RET_TRACE
When returned, this value will cause the kernel to attempt
to notify a ptrace(2)-based tracer prior to executing the
system call. If there is no tracer present, the system
call is not executed and returns a failure status with
errno set to ENOSYS.
A tracer will be notified if it requests
PTRACE_O_TRACESECCOMP using ptrace(PTRACE_SETOPTIONS).
The tracer will be notified of a PTRACE_EVENT_SECCOMP and
the SECCOMP_RET_DATA portion of the filter's return value
will be available to the tracer via PTRACE_GETEVENTMSG.
The tracer can skip the system call by changing the system
call number to -1. Alternatively, the tracer can change
the system call requested by changing the system call to a
valid system call number. If the tracer asks to skip the
system call, then the system call will appear to return
the value that the tracer puts in the return value
register.
Before Linux 4.8, the seccomp check will not be run again
after the tracer is notified. (This means that, on older
kernels, seccomp-based sandboxes must not allow use of
ptrace(2)—even of other sandboxed processes—without
extreme care; ptracers can use this mechanism to escape
from the seccomp sandbox.)
Note that a tracer process will not be notified if another
filter returns an action value with a precedence greater
than SECCOMP_RET_TRACE.
SECCOMP_RET_LOG (since Linux 4.14)
This value results in the system call being executed after
the filter return action is logged. An administrator may
override the logging of this action via the
/proc/sys/kernel/seccomp/actions_logged file.
SECCOMP_RET_ALLOW
This value results in the system call being executed.
If an action value other than one of the above is specified, then
the filter action is treated as either SECCOMP_RET_KILL_PROCESS
(since Linux 4.14) or SECCOMP_RET_KILL_THREAD (in Linux 4.13 and
earlier).
英文文档虽然又臭又长,但是不得不说,毕竟这些东西都老外写的,他们如果解释不清楚,大概这个世界上也没有人能解释清楚了。
1 | SECCOMP_RET_TRACE |
目标很明确,就是想办法调用ptrace来跳过被禁用而返回SECCOMP_RET_TRACE的调用。
板子
首先fork一个类似进程,然后父进程attach到子进程,并且同意子进程的所有被SECCOMP捕获的调用
具体ptrace的使用还挺复杂的,我查半天文档也没搞明白,还是对着别人的wp 以及 一点点尝试得到的
值得一提的是,调试过程不能使用别的调试工具,最多只能调试父进程,因为子进程被父进程附加了,如果调试器再附加上去就达不到父进程和子进程互动的效果了
1 | int main() |
如果是shellcode版本的话,为了方便,可以把SETOPTIONS也放到循环内部。
1 | int main() |
完整板子
下面是完整板子
1 | order1 = b'/bin/sh'[::-1].hex() |
随记
当时比赛由于不太清楚ptrace的使用方法,尝试了openat2,结果发现后来出题人使用了比较低的内核版本,当时还没有openat2。
我说那要不试试把栈上的环境变量全部打印出来,说不定能整个非预期,结果出题人在环境变量上放的是假flag。
出题人真的希望咱把ptrace搞懂啊哈哈哈。
houseofapple2接rop
还有就是这题前半部分的houseofapple2接rop的思路。
有些版本是使用setcontext的gadget,这题是使用svcudp_reply+26的gadget,利用houseofapple2可以控制rdi的特性,在保持控制程序流的情况下,同时控制rbp,以达到栈迁移rop的效果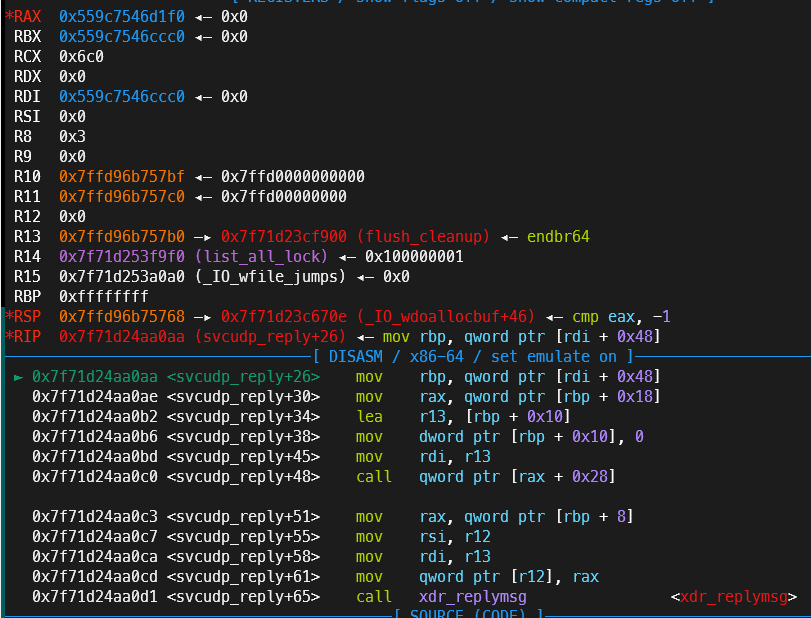
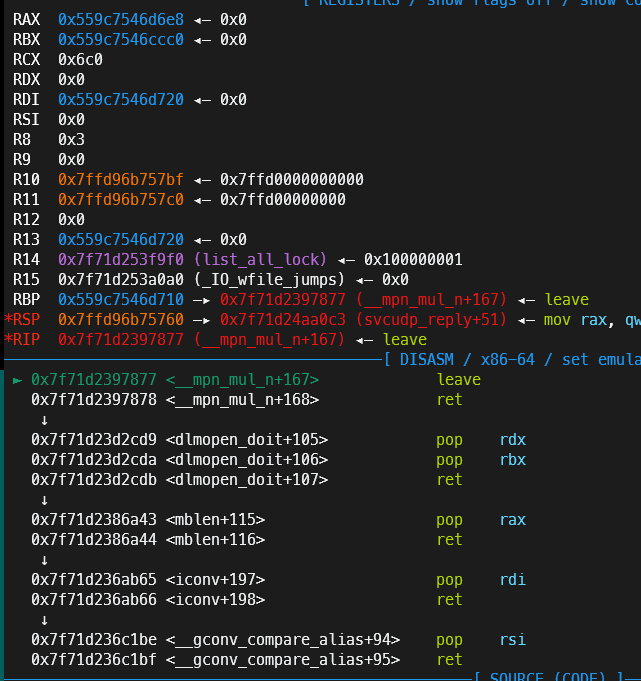
exp
下面就是完整exp,主要是留个档,哪天要是忘了一些细节在回来翻翻
1 | def debug(io): |
test.c
再下面是ptrace的测试程序,在我的环境下,gcc test.c -lseccomp才行
得加个-lseccomp参数
1 | #include <errno.h> |